Hi,
This week marks the beginning of the Mid Term Evaluations of GSoC and this post describes the pipeline employed that will be deployed to decode the video files.
The picture below depicts the basic steps involved in the task:
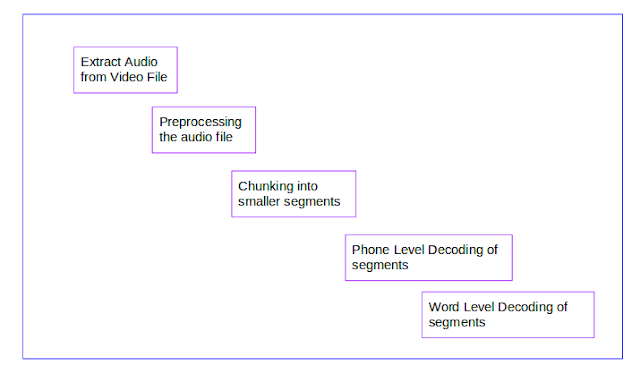
Audio Extraction from the Video Files:
For this module, I've used ffmpeg, which is a cross-platform solution to process video and audio stream. This step produces 2 channel wavefiles which have a sampling rate of 44.1khz.
I've downsampled the files to 8000 Hz and mono channel using sox, which is a command line utility in ubuntu to process audio files.
The down sampled wave files are then split into smaller chunks based on silence regions as mentioned in my first post.
As I plan to decode the files using Kaldi, I've written the scripts in such a way that the smaller chunks are saved in the format compatible with Kaldi recipe that I've built for English( as explained in my post 2).
**********************************
Code :
ffmpeg -i video_file audio_file
sox wave_file -c 1 -r 8000 wave_downsampled
sox wave_downsampled wave_downsampled 1 0.1 1% 1 0.7 1% : newfile : restart
***********************************
Decoding Using Kaldi Trained Models:
The files necessary for the process of decoding are the graphs which are present in the exp folder.
Once this is done, adjust the paths in the Kaldi recipe to point to the test files and run the decoding step. The predictions are stored in the exp folder.
The utils folder has the script int2sym.pl which is required to generate the symbols corresponding to the phones/words.
Brief Sequence of Steps:
(1) Prepares data.
(2) Prepares the Language Model.
(3) Extracts MFCC( Mel Cepstral Coefficients) features as mentioned in the previous post.
(4) Decodes the data using acoustic model trained on 100 hrs of clean Librispeech data.
The code is updated here. Feel free to have a look and suggest changes.
This week marks the beginning of the Mid Term Evaluations of GSoC and this post describes the pipeline employed that will be deployed to decode the video files.
The picture below depicts the basic steps involved in the task:

Audio Extraction from the Video Files:
For this module, I've used ffmpeg, which is a cross-platform solution to process video and audio stream. This step produces 2 channel wavefiles which have a sampling rate of 44.1khz.
I've downsampled the files to 8000 Hz and mono channel using sox, which is a command line utility in ubuntu to process audio files.
The down sampled wave files are then split into smaller chunks based on silence regions as mentioned in my first post.
As I plan to decode the files using Kaldi, I've written the scripts in such a way that the smaller chunks are saved in the format compatible with Kaldi recipe that I've built for English( as explained in my post 2).
**********************************
Code :
ffmpeg -i video_file audio_file
sox wave_file -c 1 -r 8000 wave_downsampled
sox wave_downsampled wave_downsampled 1 0.1 1% 1 0.7 1% : newfile : restart
***********************************
Decoding Using Kaldi Trained Models:
The files necessary for the process of decoding are the graphs which are present in the exp folder.
Once this is done, adjust the paths in the Kaldi recipe to point to the test files and run the decoding step. The predictions are stored in the exp folder.
The utils folder has the script int2sym.pl which is required to generate the symbols corresponding to the phones/words.
Brief Sequence of Steps:
(1) Prepares data.
(2) Prepares the Language Model.
(3) Extracts MFCC( Mel Cepstral Coefficients) features as mentioned in the previous post.
(4) Decodes the data using acoustic model trained on 100 hrs of clean Librispeech data.
The code is updated here. Feel free to have a look and suggest changes.





